Publications
Below is a list of my publications in reversed chronological order, with links to all the relevant resources such as arXiv, GitHub, slides, etc. An always up-to-date list of my papers is available on Google Scholar.
2026
- TKDE
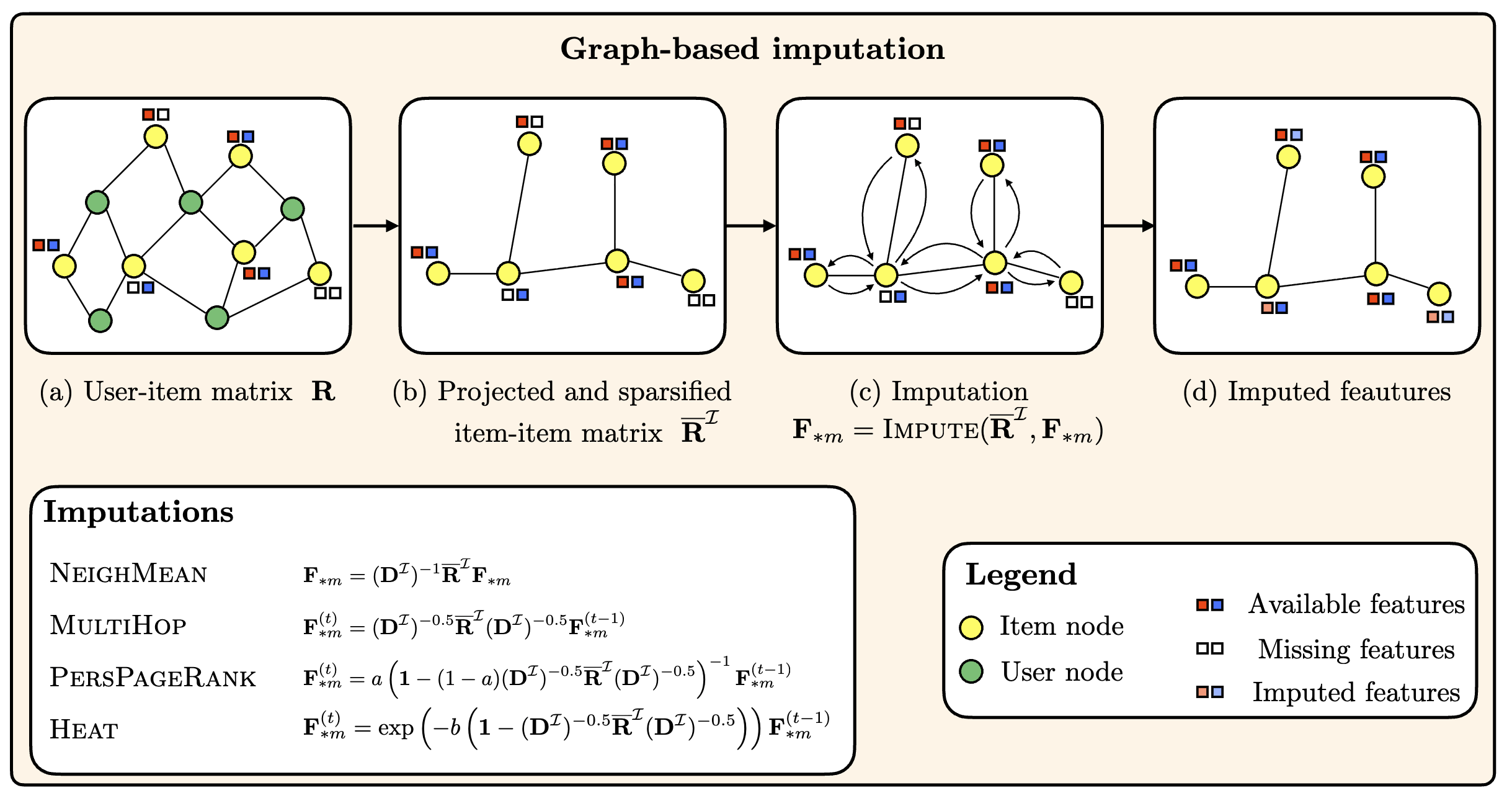 JournalTraining-Free Graph-Based Imputation of Missing Modalities in Multimodal RecommendationDaniele Malitesta, Emanuele Rossi, Claudio Pomo, and 2 more authorsIEEE Transactions on Knowledge and Data Engineering, 2026
JournalTraining-Free Graph-Based Imputation of Missing Modalities in Multimodal RecommendationDaniele Malitesta, Emanuele Rossi, Claudio Pomo, and 2 more authorsIEEE Transactions on Knowledge and Data Engineering, 2026Multimodal recommender systems (RSs) represent items in the catalog through multimodal data (e.g., product images and descriptions) that, in some cases, might be noisy or (even worse) missing. In those scenarios, the common practice is to drop items with missing modalities and train the multimodal RSs on a subsample of the original dataset. To date, the problem of missing modalities in multimodal recommendation has still received limited attention in the literature, lacking a precise formalisation as done with missing information in traditional machine learning. In this work, we first provide a problem formalisation for missing modalities in multimodal recommendation. Second, by leveraging the user-item graph structure, we re-cast the problem of missing multimodal information as a problem of graph features interpolation on the item-item co-purchase graph. On this basis, we propose four training-free approaches that propagate the available multimodal features throughout the item-item graph to impute the missing features. Extensive experiments on popular multimodal recommendation datasets demonstrate that our solutions can be seamlessly plugged into any existing multimodal RS and benchmarking framework while still preserving (or even widen) the performance gap between multimodal and traditional RSs. Moreover, we show that our graph-based techniques can perform better than traditional imputations in machine learning under different missing modalities settings. Finally, we analyse (for the first time in multimodal RSs) how feature homophily calculated on the item-item graph can influence our graph-based imputations.
@article{malitesta2026missing, title = {Training-Free Graph-Based Imputation of Missing Modalities in Multimodal Recommendation}, author = {Malitesta, Daniele and Rossi, Emanuele and Pomo, Claudio and Noia, Tommaso Di and Malliaros, Fragkiskos D.}, year = {2026}, journal = {IEEE Transactions on Knowledge and Data Engineering}, doi = {10.1109/TKDE.2026.3667005}, arxiv = {2602.17354}, } - Scientific Reports
 JournalDescription of a collaborative sperm whale birth and shifts in coda vocal styles during key eventsYaniv Aluma, Zethra Baron, Ricardo Barrett, and 44 more authorsScientific Reports, 2026
JournalDescription of a collaborative sperm whale birth and shifts in coda vocal styles during key eventsYaniv Aluma, Zethra Baron, Ricardo Barrett, and 44 more authorsScientific Reports, 2026Wild cetacean birth observations are extremely rare, with observations having been recorded in less than 10% of cetacean species. Here, we describe a detailed accounting of a sperm whale (Physeter macrocephalus) birth off the coast of Dominica within a well-documented social unit and consisted of sperm whales collaboratively lifting the newborn out of the water. We recorded data via multiple concurrent methods: underwater audio, aerial drone video, shipboard photography in addition to behavioral observations spanning before, during and after the whale birth. All 11 members from sperm whale Unit A were present and participated in the birth, which lasted 34 min from the time the flukes emerged until the completion of delivery. The sperm whale unit made extensive vocalizations, with statistically significant shifts in coda vocal style corresponding to key events, such as the beginning of the birth and interactions with short-finned pilot whales (Globicephala macrorhynchus) shortly after the birth event. An evolutionary analysis of wild cetacean births suggests that newborns being lifted out of the water dates to before the most recent common ancestor of toothed and baleen whales, > 36 million years ago, and that cooperative lifting of the newborn is noted, thus far, only in members of Odontoceti (toothed whales). This study provides the most in-depth observations of a wild cetacean birth.
@article{aluma2026collaborative_sperm_whale_birth, title = {Description of a collaborative sperm whale birth and shifts in coda vocal styles during key events}, author = {Aluma, Yaniv and Baron, Zethra and Barrett, Ricardo and Baumgartner, Courtney and Begu{\v{s}}, Ga{\v{s}}per and Bhattacharya, Sushmita and Bronstein, Michael M. and Dahan, Shlomi and Davis, Oscar and {de Haas}, Sarah and Defoe, Jullan and DelPreto, Joseph and Dess\`i, Roberto and Diamant, Roee and Gatesy, John and George, Kevin and Gero, Shane and Gibbons, Darren and Gibbons, Dean and Gil, Stephanie and Goldwasser, Shafi and Gruber, David F. and Harve, Odel and Hernandez, Alyssa and Ishay, Mapal and Jadhav, Ninad and KC, Lakshyana and Kenny, Aidan and Leitao, Antonio and Lucas, Maxime and Maalouf, Alaa and Malkin, Peter and Mevorach, Yaly and Pagani, Stefano and Paradise, Orr and Petri, Giovanni and Poetto, Simone and Rossi, Emanuele and Rus, Daniela and Salino-Hugg, Michael and Santoro, Andrea and Sharma, Pratyusha and Tchernov, Dan and Torralba, Antonio and T{\o}nnesen, Pernille and Vogt, Daniel M. and Wood, Robert J.}, year = {2026}, journal = {Scientific Reports}, volume = {16}, pages = {9206}, doi = {10.1038/s41598-025-27438-3}, }
2025
- NeurIPS
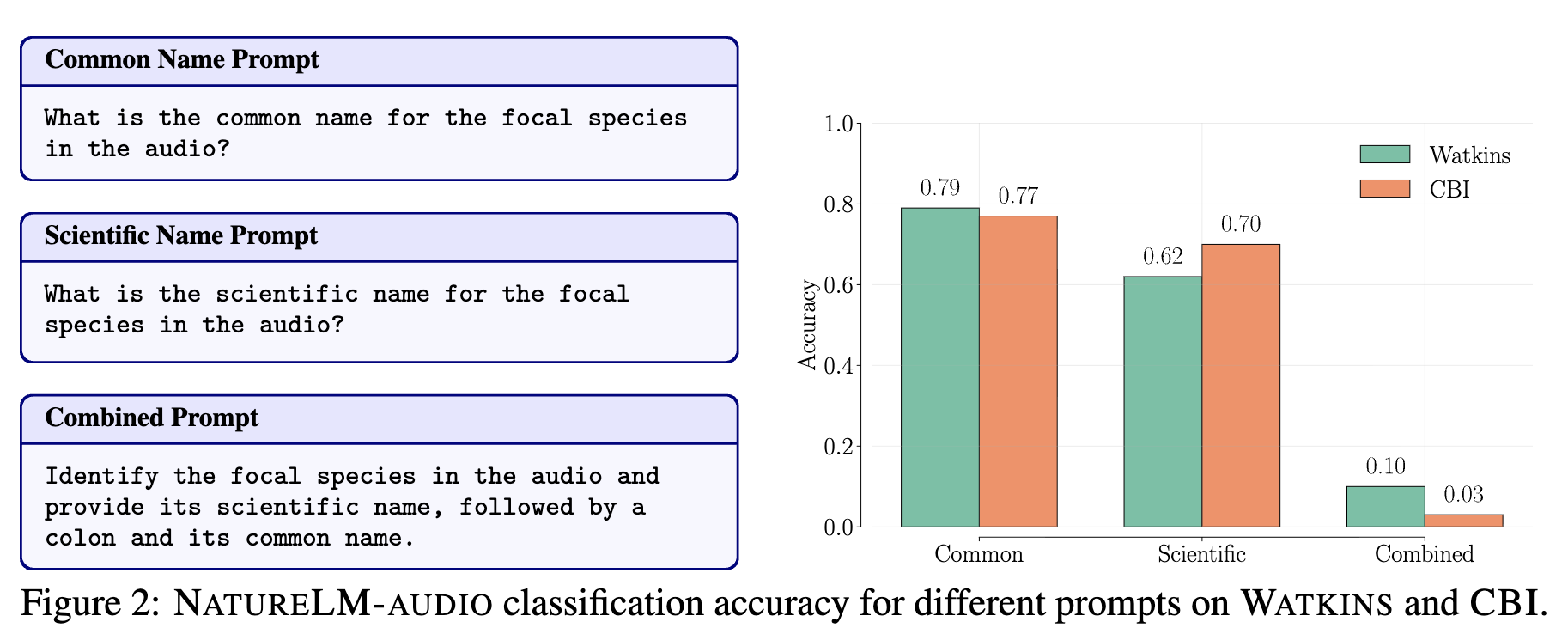 WorkshopModel Merging Improves Zero-Shot Generalization in Bioacoustic Foundation ModelsDavide Marincione, Donato Crisostomi, Roberto Dessì, and 2 more authorsNeurIPS Workshop on AI for Animal Communication, 2025
WorkshopModel Merging Improves Zero-Shot Generalization in Bioacoustic Foundation ModelsDavide Marincione, Donato Crisostomi, Roberto Dessì, and 2 more authorsNeurIPS Workshop on AI for Animal Communication, 2025Spotlight (top 15%)
Foundation models capable of generalizing across species and tasks represent a promising new frontier in bioacoustics, with NatureLM being one of the most prominent examples. While its domain-specific fine-tuning yields strong performance on bioacoustic benchmarks, we observe that it also introduces trade-offs in instruction-following flexibility. For instance, NatureLM achieves high accuracy when prompted for either the common or scientific name individually, but its accuracy drops significantly when both are requested in a single prompt. We address this by applying a simple model merging strategy that interpolates NatureLM with its base language model, recovering instruction-following capabilities with minimal loss of domain expertise. Finally, we show that the merged model exhibits markedly stronger zero-shot generalization, achieving over a 200% relative improvement and setting a new state-of-the-art in closed-set zero-shot classification of unseen species.
@article{marincione2025bio, title = {Model Merging Improves Zero-Shot Generalization in Bioacoustic Foundation Models}, author = {Marincione, Davide and Crisostomi, Donato and Dess\`i, Roberto and Rodol\`a, Emanuele and Rossi, Emanuele}, year = {2025}, journal = {NeurIPS Workshop on AI for Animal Communication}, arxiv = {2511.05171}, } - Algorithms
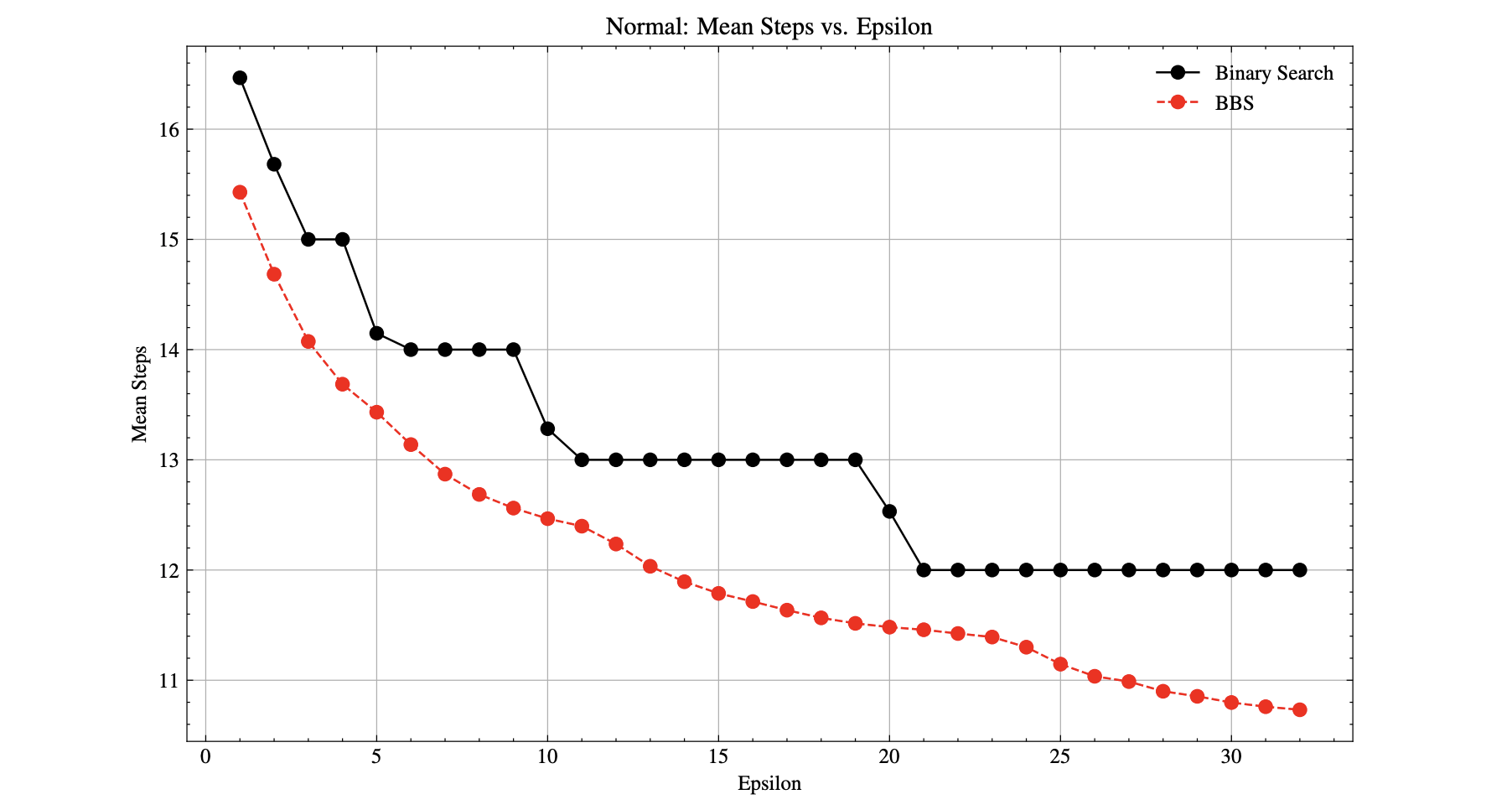 JournalBayesian Binary SearchVikash Singh, Matthew Khanzadeh, Vincent Davis, and 4 more authorsAlgorithms, 2025
JournalBayesian Binary SearchVikash Singh, Matthew Khanzadeh, Vincent Davis, and 4 more authorsAlgorithms, 2025We present Bayesian Binary Search (BBS), a novel probabilistic variant of the classical binary search/bisection algorithm. BBS leverages machine learning/statistical techniques to estimate the probability density of the search space and modifies the bisection step to split based on probability density rather than the traditional midpoint, allowing for the learned distribution of the search space to guide the search algorithm. Search space density estimation can flexibly be performed using supervised probabilistic machine learning techniques (e.g., Gaussian process regression, Bayesian neural networks, quantile regression) or unsupervised learning algorithms (e.g., Gaussian mixture models, kernel density estimation (KDE), maximum likelihood estimation (MLE)). We demonstrate significant efficiency gains of using BBS on both simulated data across a variety of distributions and in a real-world binary search use case of probing channel balances in the Bitcoin Lightning Network, for which we have deployed the BBS algorithm in a production setting.
@article{singh_bayesian_2024, title = {Bayesian Binary Search}, author = {Singh, Vikash and Khanzadeh, Matthew and Davis, Vincent and Rush, Harrison and Rossi, Emanuele and Shrader, Jesse and Lio, Pietro}, year = {2025}, journal = {Algorithms}, doi = {10.3390/a18080452}, arxiv = {2410.01771}, } - ICBC
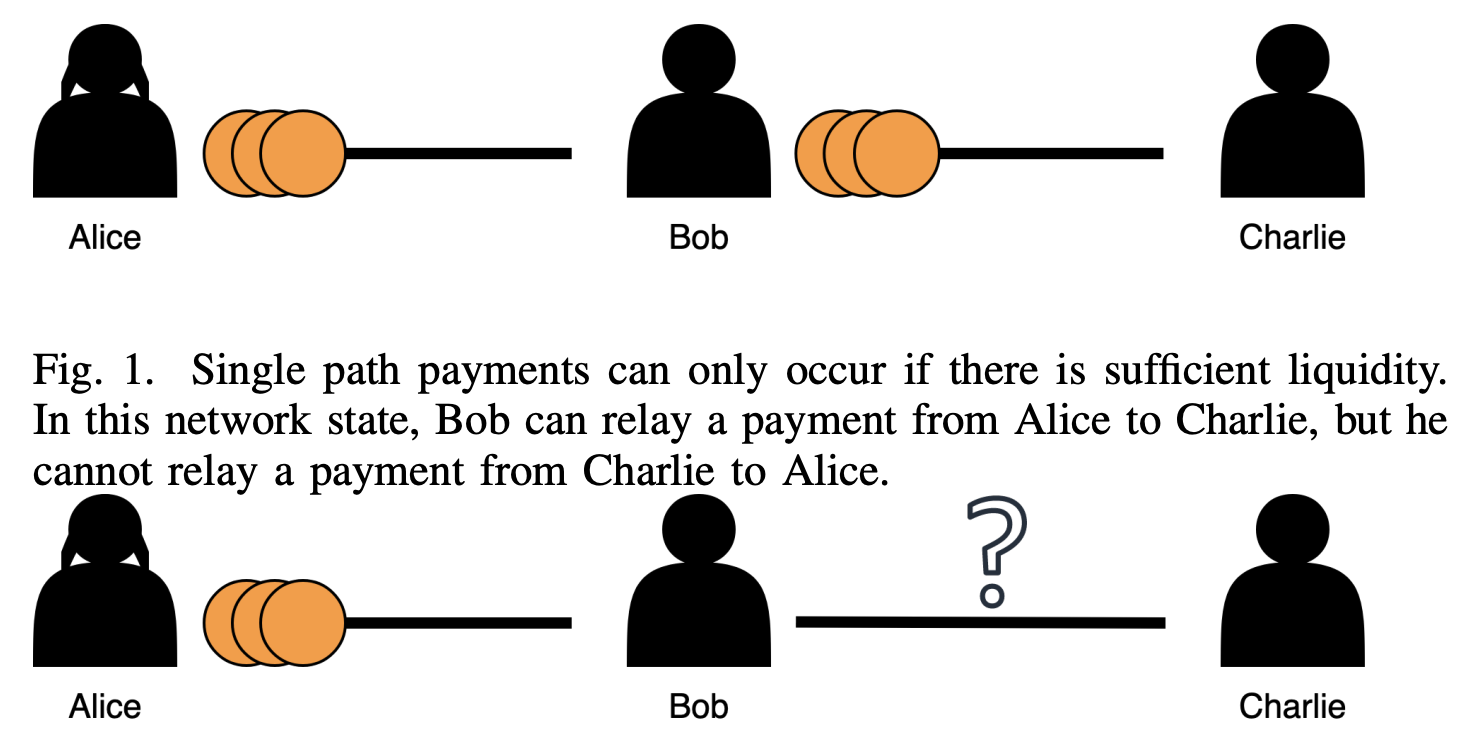 ConferenceChannel Balance Interpolation in the Lightning Network via Machine LearningVincent Davis, Vikash Singh, and Emanuele RossiIEEE International Conference on Blockchain and Cryptocurrency (ICBC), 2025
ConferenceChannel Balance Interpolation in the Lightning Network via Machine LearningVincent Davis, Vikash Singh, and Emanuele RossiIEEE International Conference on Blockchain and Cryptocurrency (ICBC), 2025The Bitcoin Lightning Network is a Layer 2 payment protocol that addresses Bitcoin’s scalability by facilitating quick and cost effective transactions through payment channels. This research explores the feasibility of using machine learning models to interpolate channel balances within the network, which can be used for optimizing the network’s pathfinding algorithms. While there has been much exploration in balance probing and multipath payment protocols, predicting channel balances using solely node and channel features remains an uncharted area. This paper evaluates the performance of several machine learning models against two heuristic baselines and investigates the predictive capabilities of various features. Our model performs favorably in experimental evaluation, outperforming by 10% against an equal split baseline where both edges are assigned half of the channel capacity.
@article{vincent_lightning_2024, title = {Channel Balance Interpolation in the Lightning Network via Machine Learning}, author = {Davis, Vincent and Singh, Vikash and Rossi, Emanuele}, year = {2025}, journal = {IEEE International Conference on Blockchain and Cryptocurrency (ICBC)}, arxiv = {2405.12087}, }
2024
- NeurIPS
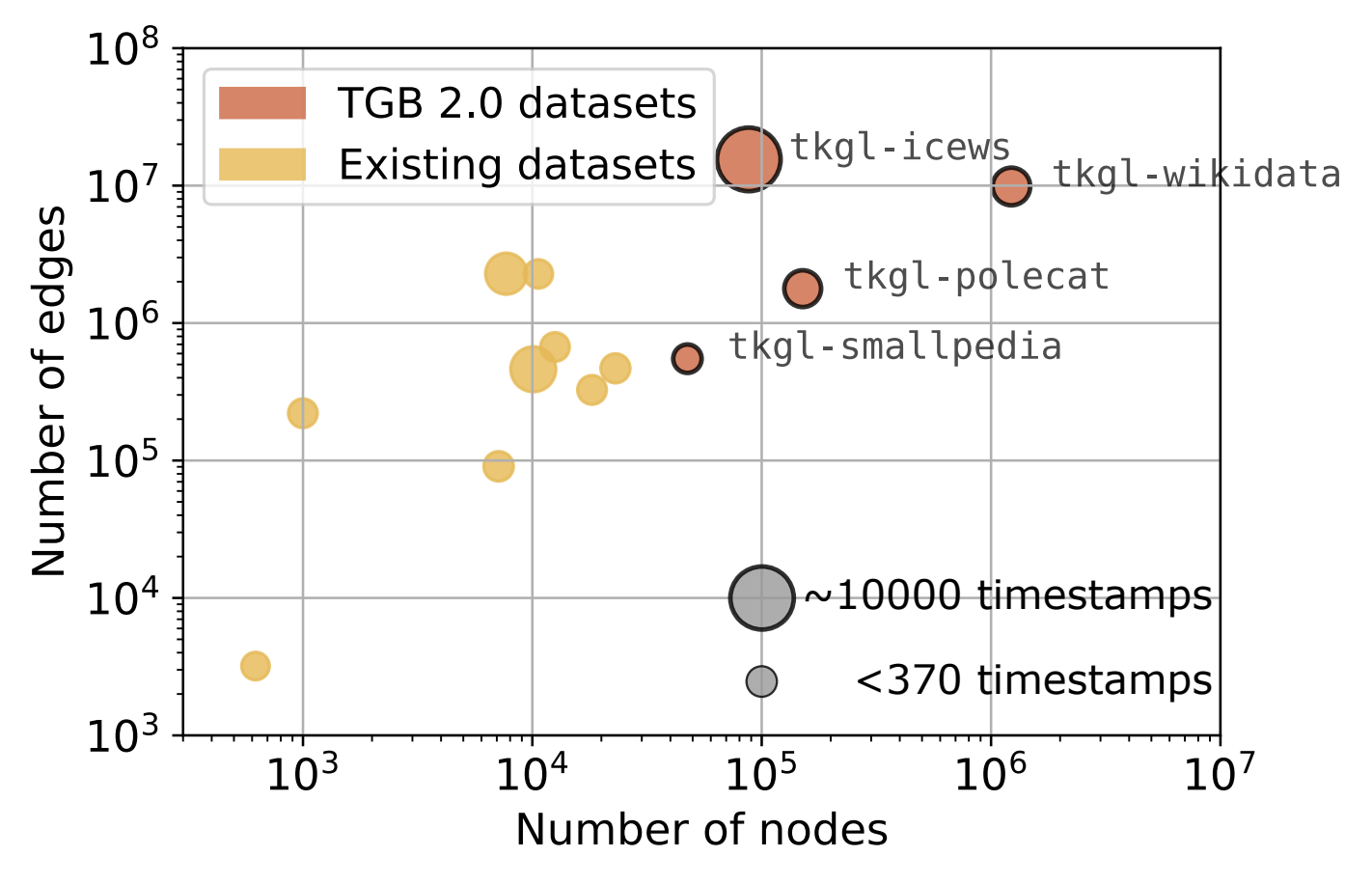 ConferenceTGB 2.0: A Benchmark for Learning on Temporal Knowledge Graphs and Heterogeneous GraphsJulia Gastinger, Shenyang Huang, Mikhail Galkin, and 9 more authorsAdvances in Neural Information Processing Systems, 2024
ConferenceTGB 2.0: A Benchmark for Learning on Temporal Knowledge Graphs and Heterogeneous GraphsJulia Gastinger, Shenyang Huang, Mikhail Galkin, and 9 more authorsAdvances in Neural Information Processing Systems, 2024Multi-relational temporal graphs are powerful tools for modeling real-world data, capturing the evolving and interconnected nature of entities over time. Recently, many novel models are proposed for ML on such graphs intensifying the need for robust evaluation and standardized benchmark datasets. However, the availability of such resources remains scarce and evaluation faces added complexity due to reproducibility issues in experimental protocols. To address these challenges, we introduce Temporal Graph Benchmark 2.0 (TGB 2.0), a novel benchmarking framework tailored for evaluating methods for predicting future links on Temporal Knowledge Graphs and Temporal Heterogeneous Graphs with a focus on large-scale datasets, extending the Temporal Graph Benchmark. TGB 2.0 facilitates comprehensive evaluations by presenting eight novel datasets spanning five domains with up to 53 million edges. TGB 2.0 datasets are significantly larger than existing datasets in terms of number of nodes, edges, or timestamps. In addition, TGB 2.0 provides a reproducible and realistic evaluation pipeline for multi-relational temporal graphs. Through extensive experimentation, we observe that 1) leveraging edge-type information is crucial to obtain high performance, 2) simple heuristic baselines are often competitive with more complex methods, 3) most methods fail to run on our largest datasets, highlighting the need for research on more scalable methods.
@article{tgb2_gastinger_2024, title = {TGB 2.0: A Benchmark for Learning on Temporal Knowledge Graphs and Heterogeneous Graphs}, author = {Gastinger, Julia and Huang, Shenyang and Galkin, Mikhail and Loghmani, Erfan and Parviz, Ali and Poursafaei, Farimah and Danovitch, Jacob and Rossi, Emanuele and Koutis, Ioannis and Stuckenschmidt, Heiner and Rabbany, Reihaneh and Rabusseau, Guillaume}, year = {2024}, journal = {Advances in Neural Information Processing Systems}, volume = {37}, pages = {140199-140229}, arxiv = {2406.09639}, } - ACM
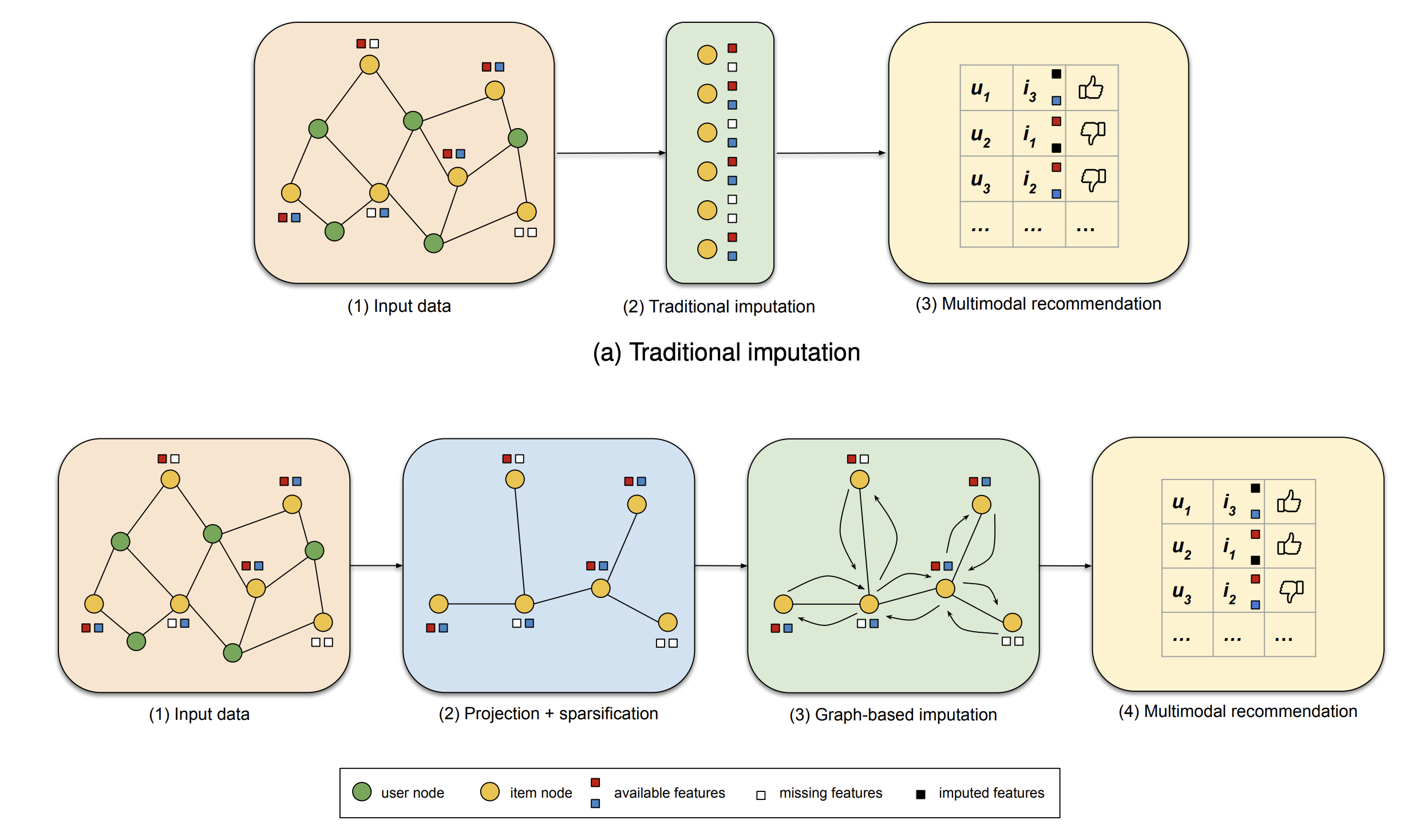 ConferenceDo We Really Need to Drop Items with Missing Modalities in Multimodal Recommendation?Daniele Malitesta, Emanuele Rossi, Claudio Pomo, and 2 more authorsProceedings of the 33rd ACM International Conference on Information, 2024
ConferenceDo We Really Need to Drop Items with Missing Modalities in Multimodal Recommendation?Daniele Malitesta, Emanuele Rossi, Claudio Pomo, and 2 more authorsProceedings of the 33rd ACM International Conference on Information, 2024Generally, items with missing modalities are dropped in multimodal recommendation. However, with this work, we question this procedure, highlighting that it would further damage the pipeline of any multimodal recommender system. First, we show that the lack of (some) modalities is, in fact, a widely-diffused phenomenon in multimodal recommendation. Second, we propose a pipeline that imputes missing multimodal features in recommendation by leveraging traditional imputation strategies in machine learning. Then, given the graph structure of the recommendation data, we also propose three more effective imputation solutions that leverage the item-item co-purchase graph and the multimodal similarities of co-interacted items. Our method can be plugged into any multimodal RSs in the literature working as an untrained pre-processing phase, showing (through extensive experiments) that any data pre-filtering is not only unnecessary but also harmful to the performance.
@article{malitesta_multimodal_2024, title = {Do We Really Need to Drop Items with Missing Modalities in Multimodal Recommendation?}, author = {Malitesta, Daniele and Rossi, Emanuele and Pomo, Claudio and Noia, Tommaso Di and Malliaros, Fragkiskos D.}, year = {2024}, journal = {Proceedings of the 33rd ACM International Conference on Information}, doi = {10.1145/3627673.3679898}, arxiv = {2408.11767}, } - bioRxiv
 PreprintPINDER: The Protein Interaction Dataset and Evaluation ResourceDaniel Kovtun, Mehmet Akdel, Alexander Goncearenco, and 16 more authorsbioRxiv, 2024
PreprintPINDER: The Protein Interaction Dataset and Evaluation ResourceDaniel Kovtun, Mehmet Akdel, Alexander Goncearenco, and 16 more authorsbioRxiv, 2024Protein-protein interactions (PPIs) are fundamental to understanding biological processes and play a key role in therapeutic advancements. As deep-learning docking methods for PPIs gain traction, benchmarking protocols and datasets tailored for effective training and evaluation of their generalization capabilities and performance across real-world scenarios become imperative. Aiming to overcome limitations of existing approaches, we introduce PINDER, a comprehensive annotated dataset that uses structural clustering to derive non-redundant interface-based data splits and includes holo (bound), apo (unbound), and computationally predicted structures. PINDER consists of 2,319,564 dimeric PPI systems (and up to 25 million augmented PPIs) and 1,955 high-quality test PPIs with interface data leakage removed. Additionally, PINDER provides a test subset with 180 dimers for comparison to AlphaFold-Multimer without any interface leakage with respect to its training set. Unsurprisingly, the PINDER benchmark reveals that the performance of existing docking models is highly overestimated when evaluated on leaky test sets. Most importantly, by retraining DiffDock-PP on PINDER interface-clustered splits, we show that interface cluster-based sampling of the training split, along with the diverse and less leaky validation split, leads to strong generalization improvements.
@article{kovtun_pinder_2024, title = {PINDER: The Protein Interaction Dataset and Evaluation Resource}, author = {Kovtun, Daniel and Akdel, Mehmet and Goncearenco, Alexander and Zhou, Guoqing and Holt, Graham and Baugher, David and Lin, Dejun and Adeshina, Yusuf and Castiglione, Thomas and Wang, Xiaoyun and Marquet, Céline and McPartlon, Matt and Geffner, Tomas and Corso, Gabriele and Stärk, Hannes and Carpenter, Zachary and Kucukbenli, Emine and Bronstein, Michael and Naef, Luca}, year = {2024}, journal = {bioRxiv}, biorxiv = {2024.07.17.603980v4}, } - ICML
 WorkshopPLINDER: The Protein-Ligand Interactions Dataset and Evaluation ResourceJanani Durairaj, Yusuf Adeshina, Zhonglin Cao, and 20 more authorsICML ML for Life and Material Science Workshop, 2024
WorkshopPLINDER: The Protein-Ligand Interactions Dataset and Evaluation ResourceJanani Durairaj, Yusuf Adeshina, Zhonglin Cao, and 20 more authorsICML ML for Life and Material Science Workshop, 2024Protein-protein interactions (PPIs) are fundamental to understanding biological processes and play a key role in therapeutic advancements. As deep-learning docking methods for PPIs gain traction, benchmarking protocols and datasets tailored for effective training and evaluation of their generalization capabilities and performance across real-world scenarios become imperative. Aiming to overcome limitations of existing approaches, we introduce PINDER, a comprehensive annotated dataset that uses structural clustering to derive non-redundant interface-based data splits and includes holo (bound), apo (unbound), and computationally predicted structures. PINDER consists of 2,319,564 dimeric PPI systems (and up to 25 million augmented PPIs) and 1,955 high-quality test PPIs with interface data leakage removed. Additionally, PINDER provides a test subset with 180 dimers for comparison to AlphaFold-Multimer without any interface leakage with respect to its training set. Unsurprisingly, the PINDER benchmark reveals that the performance of existing docking models is highly overestimated when evaluated on leaky test sets. Most importantly, by retraining DiffDock-PP on PINDER interface-clustered splits, we show that interface cluster-based sampling of the training split, along with the diverse and less leaky validation split, leads to strong generalization improvements.
@article{durairaj_plinder_2024, title = {PLINDER: The Protein-Ligand Interactions Dataset and Evaluation Resource}, author = {Durairaj, Janani and Adeshina, Yusuf and Cao, Zhonglin and Zhang, Xuejin and Oleinikovas, Vladas and Duignan, Thomas and McClure, Zachary and Robin, Xavier and Kovtun, Danny and Rossi, Emanuele and Zhou, Guoqing and Veccham, Srimukh and Isert, Clemens and Peng, Yuxing and Sundareson, Prabindh and Akdel, Mehmet and Corso, Gabriele and Stärk, Hannes and Carpenter, Zachary and Bronstein, Michael and Kucukbenli, Emine and Schwede, Torsten and Naef, Luca}, year = {2024}, journal = {ICML ML for Life and Material Science Workshop}, biorxiv = {2024.07.17.603980v4}, } - LoG
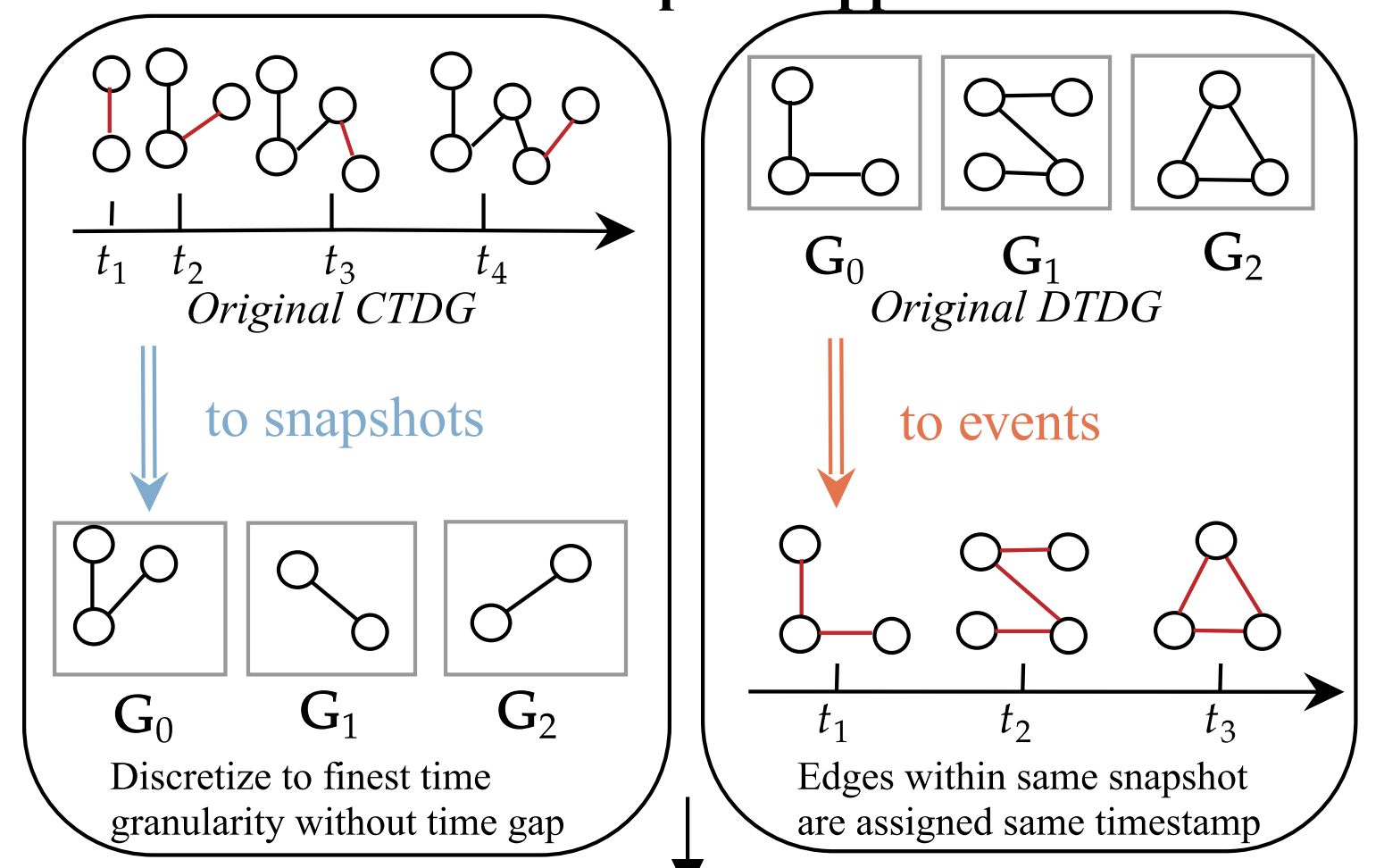 ConferenceUTG: Towards a Unified View of Snapshot and Event Based Models for Temporal GraphsShenyang Huang, Farimah Poursafaei, Reihaneh Rabbany, and 2 more authorsLearning on Graphs Conference (LoG), 2024
ConferenceUTG: Towards a Unified View of Snapshot and Event Based Models for Temporal GraphsShenyang Huang, Farimah Poursafaei, Reihaneh Rabbany, and 2 more authorsLearning on Graphs Conference (LoG), 2024Many real world graphs are inherently dynamic, constantly evolving with node and edge additions. These graphs can be represented by temporal graphs, either through a stream of edge events or a sequence of graph snapshots. Until now, the development of machine learning methods for both types has occurred largely in isolation, resulting in limited experimental comparison and theoretical crosspollination between the two. In this paper, we introduce Unified Temporal Graph (UTG), a framework that unifies snapshot-based and event-based machine learning models under a single umbrella, enabling models developed for one representation to be applied effectively to datasets of the other. We also propose a novel UTG training procedure to boost the performance of snapshot-based models in the streaming setting. We comprehensively evaluate both snapshot and event-based models across both types of temporal graphs on the temporal link prediction task. Our main findings are threefold: first, when combined with UTG training, snapshot-based models can perform competitively with event-based models such as TGN and GraphMixer even on event datasets. Second, snapshot-based models are at least an order of magnitude faster than most event-based models during inference. Third, while event-based methods such as NAT and DyGFormer outperforms snapshot-based methods on both types of temporal graphs, this is because they leverage joint neighborhood structural features thus emphasizing the potential to incorporate these features into snapshotbased models as well. These findings highlight the importance of comparing model architectures independent of the data format and suggest the potential of combining the efficiency of snapshot-based models with the performance of event-based models in the future.
@article{huang_utg_2024, title = {UTG: Towards a Unified View of Snapshot and Event Based Models for Temporal Graphs}, author = {Huang, Shenyang and Poursafaei, Farimah and Rabbany, Reihaneh and Rabusseau, Guillaume and Rossi, Emanuele}, year = {2024}, journal = {Learning on Graphs Conference (LoG)}, arxiv = {2407.12269}, } - PhD Thesis
 ThesisDeep Learning on Real-World GraphsEmanuele RossiImperial College London, 2024
ThesisDeep Learning on Real-World GraphsEmanuele RossiImperial College London, 2024Graph Neural Networks (GNNs) have become a central tool for learning on graph-structured data, yet their applicability to real-world systems remains limited by key challenges such as scalability, temporality, directionality, data incompleteness, and structural uncertainty. This thesis introduces a series of models addressing these limitations: SIGN for scalable graph learning, TGN for temporal graphs, Dir-GNN for directed and heterophilic networks, Feature Propagation (FP) for learning with missing node features, and NuGget for game-theoretic structural inference. Together, these contributions bridge the gap between academic benchmarks and industrial-scale graphs, enabling the use of GNNs in domains such as social and recommender systems.
@phdthesis{rossi2024thesis, title = {Deep Learning on Real-World Graphs}, author = {Rossi, Emanuele}, year = {2024}, school = {Imperial College London}, doi = {10.25560/112863}, arxiv = {2510.21994}, }
2023
- NeurIPS
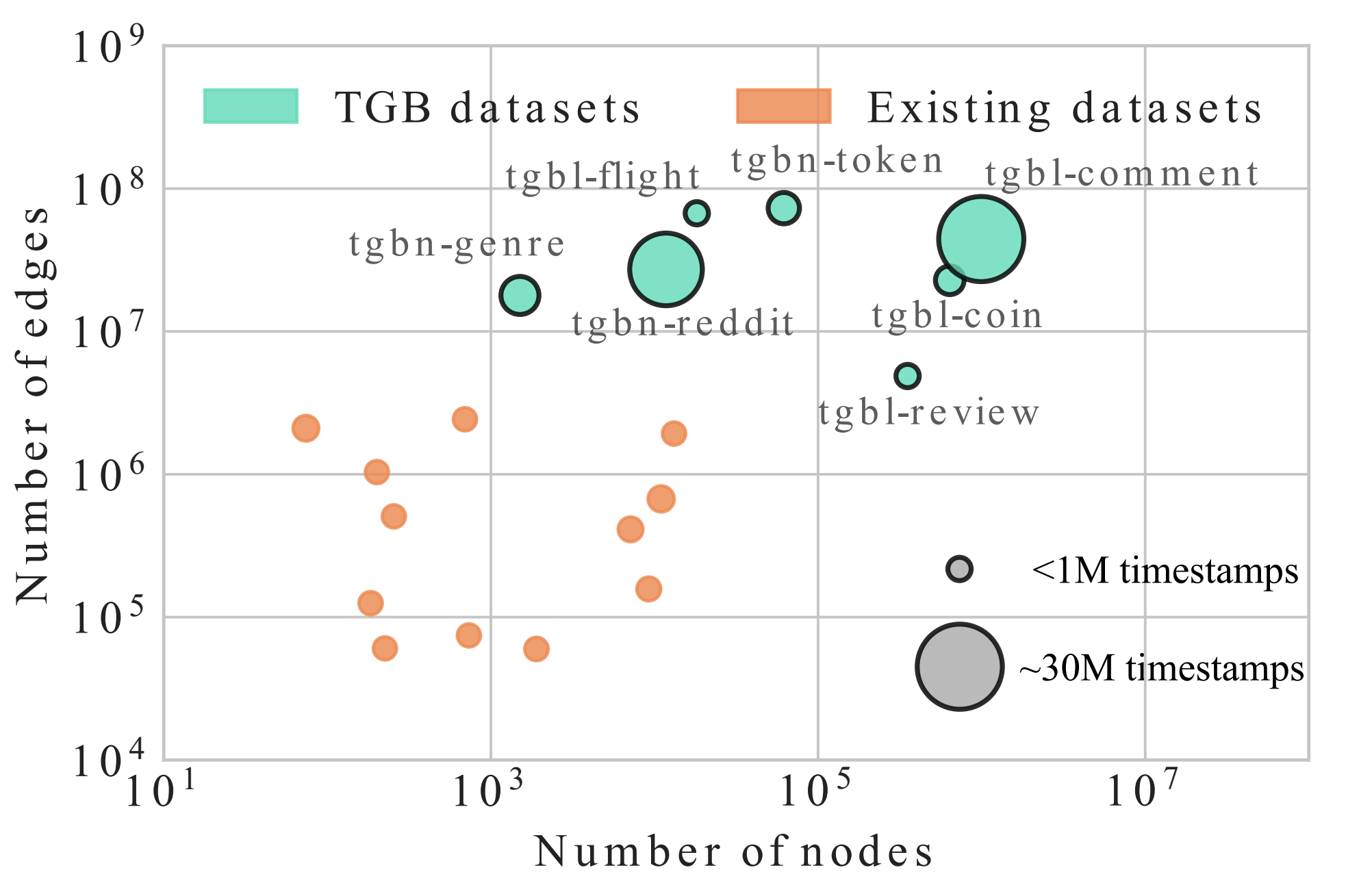 ConferenceTemporal Graph Benchmark for Machine Learning on Temporal GraphsShenyang Huang, Farimah Poursafaei, Jacob Danovitch, and 7 more authorsAdvances in Neural Information Processing Systems, 2023
ConferenceTemporal Graph Benchmark for Machine Learning on Temporal GraphsShenyang Huang, Farimah Poursafaei, Jacob Danovitch, and 7 more authorsAdvances in Neural Information Processing Systems, 2023We present the Temporal Graph Benchmark (TGB), a collection of challenging and diverse benchmark datasets for realistic, reproducible, and robust evaluation of machine learning models on temporal graphs. TGB datasets are of large scale, spanning years in duration, incorporate both node and edge-level prediction tasks and cover a diverse set of domains including social, trade, transaction, and transportation networks. For both tasks, we design evaluation protocols based on realistic use-cases. We extensively benchmark each dataset and find that the performance of common models can vary drastically across datasets. In addition, on dynamic node property prediction tasks, we show that simple methods often achieve superior performance compared to existing temporal graph models. We believe that these findings open up opportunities for future research on temporal graphs. Finally, TGB provides an automated machine learning pipeline for reproducible and accessible temporal graph research, including data loading, experiment setup and performance evaluation. TGB will be maintained and updated on a regular basis and welcomes community feedback. TGB datasets, data loaders, example codes, evaluation setup, and leaderboards are publicly available at this https URL.
@article{tgb_huang_2023, title = {Temporal Graph Benchmark for Machine Learning on Temporal Graphs}, author = {Huang, Shenyang and Poursafaei, Farimah and Danovitch, Jacob and Fey, Matthias and Hu, Weihua and Rossi, Emanuele and Leskovec, Jure and Bronstein, Michael M. and Rabusseau, Guillaume and Rabbany, Reihaneh}, year = {2023}, journal = {Advances in Neural Information Processing Systems}, arxiv = {2307.01026}, } - LoG
 ConferenceEdge Directionality Improves Learning on Heterophilic GraphsEmanuele Rossi, Bertrand Charpentier, Francesco Di Giovanni, and 3 more authorsLearning on Graphs Conference (LoG), 2023
ConferenceEdge Directionality Improves Learning on Heterophilic GraphsEmanuele Rossi, Bertrand Charpentier, Francesco Di Giovanni, and 3 more authorsLearning on Graphs Conference (LoG), 2023Graph Neural Networks (GNNs) have become the de-facto standard tool for modeling relational data. However, while many real-world graphs are directed, the majority of today’s GNN models discard this information altogether by simply making the graph undirected. The reasons for this are historical: 1) many early variants of spectral GNNs explicitly required undirected graphs, and 2) the first benchmarks on homophilic graphs did not find significant gain from using direction. In this paper, we show that in heterophilic settings, treating the graph as directed increases the effective homophily of the graph, suggesting a potential gain from the correct use of directionality information. To this end, we introduce Directed Graph Neural Network (Dir-GNN), a novel general framework for deep learning on directed graphs. Dir-GNN can be used to extend any Message Passing Neural Network (MPNN) to account for edge directionality information by performing separate aggregations of the incoming and outgoing edges. We prove that Dir-GNN matches the expressivity of the Directed Weisfeiler-Lehman test, exceeding that of conventional MPNNs. In extensive experiments, we validate that while our framework leaves performance unchanged on homophilic datasets, it leads to large gains over base models such as GCN, GAT and GraphSage on heterophilic benchmarks, outperforming much more complex methods and achieving new state-of-the-art results.
@article{dirgnn_rossi_2023, title = {Edge Directionality Improves Learning on Heterophilic Graphs}, author = {Rossi, Emanuele and Charpentier, Bertrand and Giovanni, Francesco Di and Frasca, Fabrizio and Günnemann, Stephan and Bronstein, Michael M.}, year = {2023}, journal = {Learning on Graphs Conference (LoG)}, arxiv = {2305.10498}, }
2022
- ICLR
 ConferenceGraph Neural Networks for Link Prediction with Subgraph SketchingBen Chamberlain, Sergey Shirobokov, Emanuele Rossi, and 5 more authorsInternational Conference on Learning Representations (ICLR), 2022
ConferenceGraph Neural Networks for Link Prediction with Subgraph SketchingBen Chamberlain, Sergey Shirobokov, Emanuele Rossi, and 5 more authorsInternational Conference on Learning Representations (ICLR), 2022Oral (top 5%)
Many Graph Neural Networks (GNNs) perform poorly compared to simple heuristics on Link Prediction (LP) tasks. This is due to limitations in expressive power such as the inability to count triangles (the backbone of most LP heuristics) and because they can not distinguish automorphic nodes (those having identical structural roles). Both expressiveness issues can be alleviated by learning link (rather than node) representations and incorporating structural features such as triangle counts. Since explicit link representations are often prohibitively expensive, recent works resorted to subgraph-based methods, which have achieved state-of-the-art performance for LP, but suffer from poor efficiency due to high levels of redundancy between subgraphs. We analyze the components of subgraph GNN (SGNN) methods for link prediction. Based on our analysis, we propose a novel full-graph GNN called ELPH (Efficient Link Prediction with Hashing) that passes subgraph sketches as messages to approximate the key components of SGNNs without explicit subgraph construction. ELPH is provably more expressive than Message Passing GNNs (MPNNs). It outperforms existing SGNN models on many standard LP benchmarks while being orders of magnitude faster. However, it shares the common GNN limitation that it is only efficient when the dataset fits in GPU memory. Accordingly, we develop a highly scalable model, called BUDDY, which uses feature precomputation to circumvent this limitation without sacrificing predictive performance. Our experiments show that BUDDY also outperforms SGNNs on standard LP benchmarks while being highly scalable and faster than ELPH.
@article{chamberlain2022lpsketching, title = {Graph Neural Networks for Link Prediction with Subgraph Sketching}, author = {Chamberlain, Ben and Shirobokov, Sergey and Rossi, Emanuele and Frasca, Fabrizio and Markovich, Thomas and Hammerla, Nils and Bronstein, Michael M. and Hansmire, Max}, year = {2022}, journal = {International Conference on Learning Representations (ICLR)}, arxiv = {2209.15486}, } - AAAI
 ConferenceProvably Efficient Causal Model-Based Reinforcement Learning for Systematic GeneralizationMirco Mutti, Riccardo De Santi, Emanuele Rossi, and 3 more authorsProceedings of the AAAI Conference on Artificial Intelligence, 2022
ConferenceProvably Efficient Causal Model-Based Reinforcement Learning for Systematic GeneralizationMirco Mutti, Riccardo De Santi, Emanuele Rossi, and 3 more authorsProceedings of the AAAI Conference on Artificial Intelligence, 2022In the sequential decision making setting, an agent aims to achieve systematic generalization over a large, possibly infinite, set of environments. Such environments are modeled as discrete Markov decision processes with both states and actions represented through a feature vector. The underlying structure of the environments allows the transition dynamics to be factored into two components: one that is environment-specific and another that is shared. Consider a set of environments that share the laws of motion as an example. In this setting, the agent can take a finite amount of reward-free interactions from a subset of these environments. The agent then must be able to approximately solve any planning task defined over any environment in the original set, relying on the above interactions only. Can we design a provably efficient algorithm that achieves this ambitious goal of systematic generalization? In this paper, we give a partially positive answer to this question. First, we provide a tractable formulation of systematic generalization by employing a causal viewpoint. Then, under specific structural assumptions, we provide a simple learning algorithm that guarantees any desired planning error up to an unavoidable sub-optimality term, while showcasing a polynomial sample complexity.
@article{mutti2022causalrl, title = {Provably Efficient Causal Model-Based Reinforcement Learning for Systematic Generalization}, author = {Mutti, Mirco and Santi, Riccardo De and Rossi, Emanuele and Calderon, Juan Felipe and Bronstein, Michael M. and Restelli, Marcello}, year = {2022}, journal = {Proceedings of the AAAI Conference on Artificial Intelligence}, doi = {10.1609/aaai.v37i8.26109}, arxiv = {2202.06545}, } - ICML
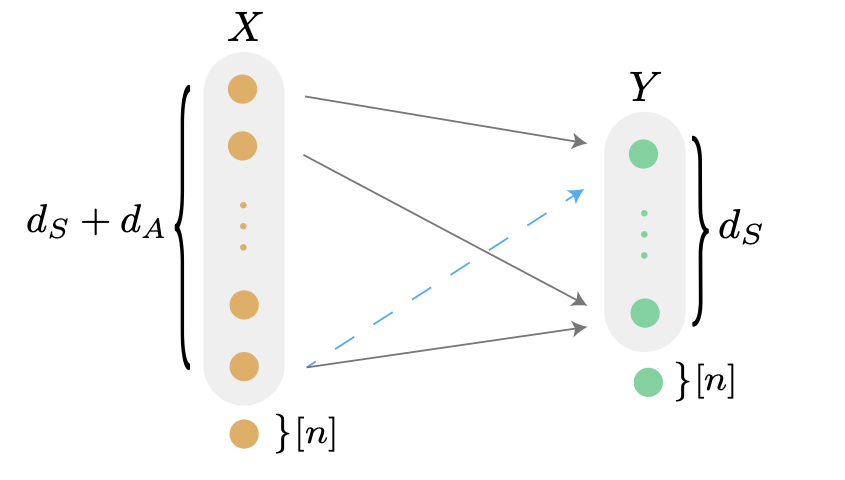
 ConferenceLearning to Infer Structures of Network GamesEmanuele Rossi, Federico Monti, Yan Leng, and 2 more authorsProceedings of the 39th International Conference on Machine Learning, ICML, 2022
ConferenceLearning to Infer Structures of Network GamesEmanuele Rossi, Federico Monti, Yan Leng, and 2 more authorsProceedings of the 39th International Conference on Machine Learning, ICML, 2022Strategic interactions between a group of individuals or organisations can be modelled as games played on networks, where a player’s payoff depends not only on their actions but also on those of their neighbours. Inferring the network structure from observed game outcomes (equilibrium actions) is an important problem with numerous potential applications in economics and social sciences. Existing methods mostly require the knowledge of the utility function associated with the game, which is often unrealistic to obtain in real-world scenarios. We adopt a transformer-like architecture which correctly accounts for the symmetries of the problem and learns a mapping from the equilibrium actions to the network structure of the game without explicit knowledge of the utility function. We test our method on three different types of network games using both synthetic and real-world data, and demonstrate its effectiveness in network structure inference and superior performance over existing methods.
@article{rossi2022networkgames, title = {Learning to Infer Structures of Network Games}, author = {Rossi, Emanuele and Monti, Federico and Leng, Yan and Bronstein, Michael M. and Dong, Xiaowen}, year = {2022}, journal = {Proceedings of the 39th International Conference on Machine Learning, {ICML}}, arxiv = {2206.08119}, } - LoG
 ConferenceOn the Unreasonable Effectiveness of Feature propagation in Learning on Graphs with Missing Node FeaturesEmanuele Rossi, Henry Kenlay, Maria I. Gorinova, and 3 more authorsLearning on Graphs Conference (LoG), 2022
ConferenceOn the Unreasonable Effectiveness of Feature propagation in Learning on Graphs with Missing Node FeaturesEmanuele Rossi, Henry Kenlay, Maria I. Gorinova, and 3 more authorsLearning on Graphs Conference (LoG), 2022While Graph Neural Networks (GNNs) have recently become the de facto standard for modeling relational data, they impose a strong assumption on the availability of the node or edge features of the graph. In many real-world applications, however, features are only partially available; for example, in social networks, age and gender are available only for a small subset of users. We present a general approach for handling missing features in graph machine learning applications that is based on minimization of the Dirichlet energy and leads to a diffusion-type differential equation on the graph. The discretization of this equation produces a simple, fast and scalable algorithm which we call Feature Propagation. We experimentally show that the proposed approach outperforms previous methods on seven common node-classification benchmarks and can withstand surprisingly high rates of missing features: on average we observe only around 4% relative accuracy drop when 99% of the features are missing. Moreover, it takes only 10 seconds to run on a graph with ∼2.5M nodes and ∼123M edges on a single GPU.
@article{rossi2021fp, title = {On the Unreasonable Effectiveness of Feature propagation in Learning on Graphs with Missing Node Features}, author = {Rossi, Emanuele and Kenlay, Henry and Gorinova, Maria I. and Chamberlain, Ben and Dong, Xiaowen and Bronstein, Michael M.}, year = {2022}, journal = {Learning on Graphs Conference (LoG)}, arxiv = {2111.12128}, }
2021
- ICML
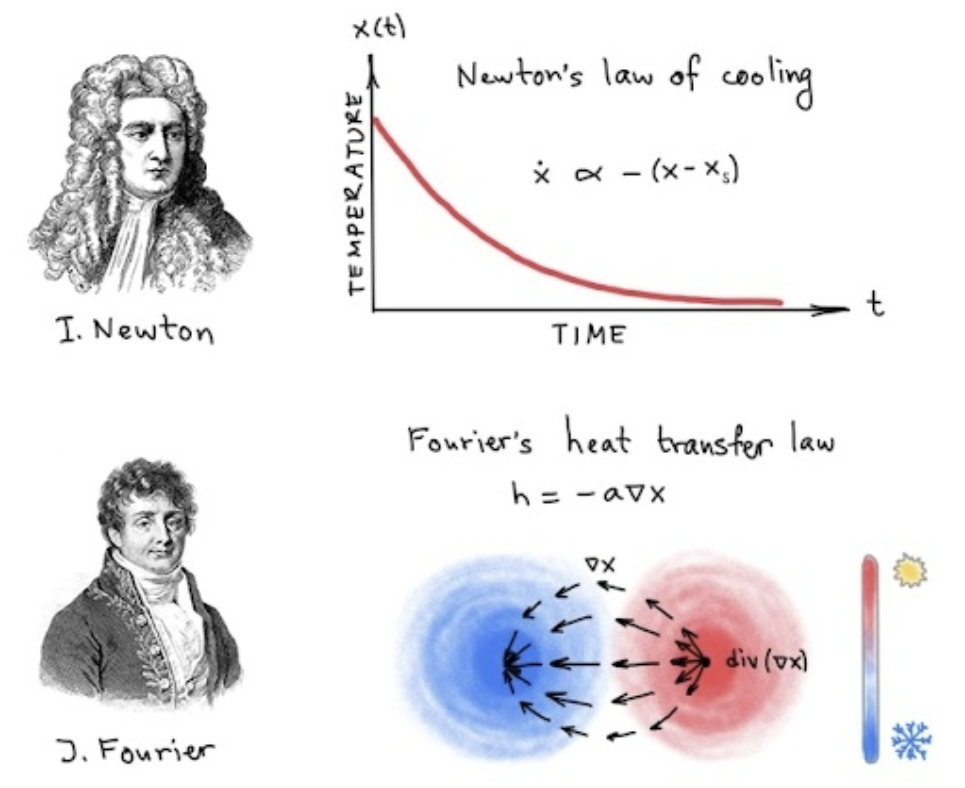 ConferenceGRAND: Graph Neural DiffusionBen Chamberlain, James Rowbottom, Maria I. Gorinova, and 3 more authorsProceedings of the 38th International Conference on Machine Learning, ICML, 2021
ConferenceGRAND: Graph Neural DiffusionBen Chamberlain, James Rowbottom, Maria I. Gorinova, and 3 more authorsProceedings of the 38th International Conference on Machine Learning, ICML, 2021We present Graph Neural Diffusion (GRAND) that approaches deep learning on graphs as a continuous diffusion process and treats Graph Neural Networks (GNNs) as discretisations of an underlying PDE. In our model, the layer structure and topology correspond to the discretisation choices of temporal and spatial operators. Our approach allows a principled development of a broad new class of GNNs that are able to address the common plights of graph learning models such as depth, oversmoothing, and bottlenecks. Key to the success of our models are stability with respect to perturbations in the data and this is addressed for both implicit and explicit discretisation schemes. We develop linear and nonlinear versions of GRAND, which achieve competitive results on many standard graph benchmarks.
@article{chamberlain2021grand, title = {GRAND: Graph Neural Diffusion}, author = {Chamberlain, Ben and Rowbottom, James and Gorinova, Maria I. and Webb, Stefan D. and Rossi, Emanuele and Bronstein, Michael M.}, year = {2021}, journal = {Proceedings of the 38th International Conference on Machine Learning, {ICML}}, arxiv = {2106.10934}, }
2020
- RecSys
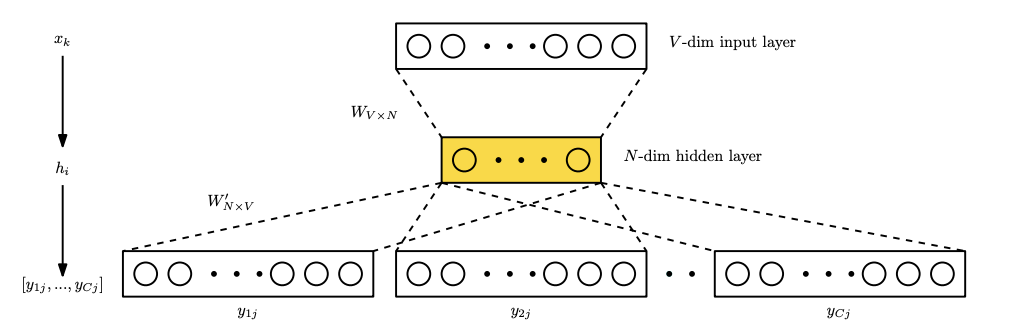 ConferenceTuning Word2vec for Large Scale Recommendation SystemsBen Chamberlain, Emanuele Rossi, Dan Shiebler, and 2 more authorsRecSys - 14th ACM Conference on Recommender Systems, 2020
ConferenceTuning Word2vec for Large Scale Recommendation SystemsBen Chamberlain, Emanuele Rossi, Dan Shiebler, and 2 more authorsRecSys - 14th ACM Conference on Recommender Systems, 2020Word2vec is a powerful machine learning tool that emerged from Natural Lan-guage Processing (NLP) and is now applied in multiple domains, including recom-mender systems, forecasting, and network analysis. As Word2vec is often used offthe shelf, we address the question of whether the default hyperparameters are suit-able for recommender systems. The answer is emphatically no. In this paper, wefirst elucidate the importance of hyperparameter optimization and show that un-constrained optimization yields an average 221% improvement in hit rate over thedefault parameters. However, unconstrained optimization leads to hyperparametersettings that are very expensive and not feasible for large scale recommendationtasks. To this end, we demonstrate 138% average improvement in hit rate with aruntime budget-constrained hyperparameter optimization. Furthermore, to makehyperparameter optimization applicable for large scale recommendation problemswhere the target dataset is too large to search over, we investigate generalizinghyperparameters settings from samples. We show that applying constrained hy-perparameter optimization using only a 10% sample of the data still yields a 91%average improvement in hit rate over the default parameters when applied to thefull datasets. Finally, we apply hyperparameters learned using our method of con-strained optimization on a sample to the Who To Follow recommendation serviceat Twitter and are able to increase follow rates by 15%.
@article{chamberlain2020word2vec, title = {Tuning Word2vec for Large Scale Recommendation Systems}, author = {Chamberlain, Ben and Rossi, Emanuele and Shiebler, Dan and Sedhain, Suvash and Bronstein, Michael}, year = {2020}, journal = {RecSys - 14th ACM Conference on Recommender Systems}, doi = {10.1145/3383313.3418486}, arxiv = {2009.12192}, } - ICML
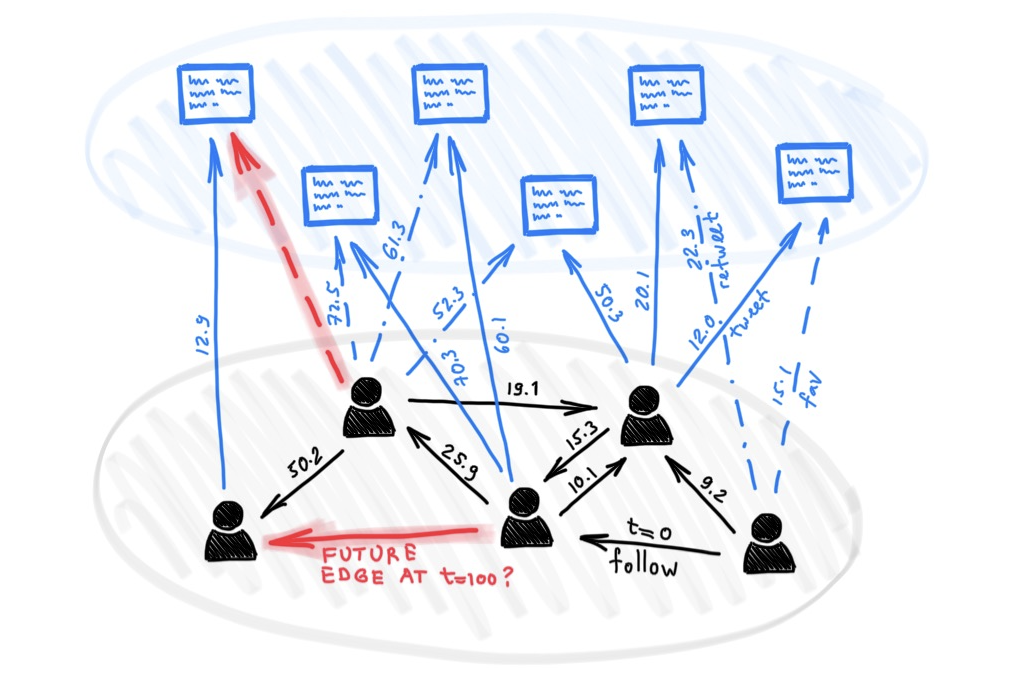 WorkshopTemporal Graph Networks for Deep Learning on Dynamic GraphsEmanuele Rossi, Ben Chamberlain, Fabrizio Frasca, and 3 more authorsICML Workshop on Graph Representation Learning, 2020
WorkshopTemporal Graph Networks for Deep Learning on Dynamic GraphsEmanuele Rossi, Ben Chamberlain, Fabrizio Frasca, and 3 more authorsICML Workshop on Graph Representation Learning, 2020Graph Neural Networks (GNNs) have recently become increasingly popular due to their ability to learn complex systems of relations or interactions arising in a broad spectrum of problems ranging from biology and particle physics to social networks and recommendation systems. Despite the plethora of different models for deep learning on graphs, few approaches have been proposed thus far for dealing with graphs that present some sort of dynamic nature (e.g. evolving features or connectivity over time). In this paper, we present Temporal Graph Networks (TGNs), a generic, efficient framework for deep learning on dynamic graphs represented as sequences of timed events. Thanks to a novel combination of memory modules and graph-based operators, TGNs are able to significantly outperform previous approaches being at the same time more computationally efficient. We furthermore show that several previous models for learning on dynamic graphs can be cast as specific instances of our framework. We perform a detailed ablation study of different components of our framework and devise the best configuration that achieves state-of-the-art performance on several transductive and inductive prediction tasks for dynamic graphs.
@article{rossi2020tgn, title = {Temporal Graph Networks for Deep Learning on Dynamic Graphs}, author = {Rossi, Emanuele and Chamberlain, Ben and Frasca, Fabrizio and Eynard, Davide and Monti, Federico and Bronstein, Michael}, year = {2020}, journal = {ICML Workshop on Graph Representation Learning}, arxiv = {2006.10637}, } - ICML
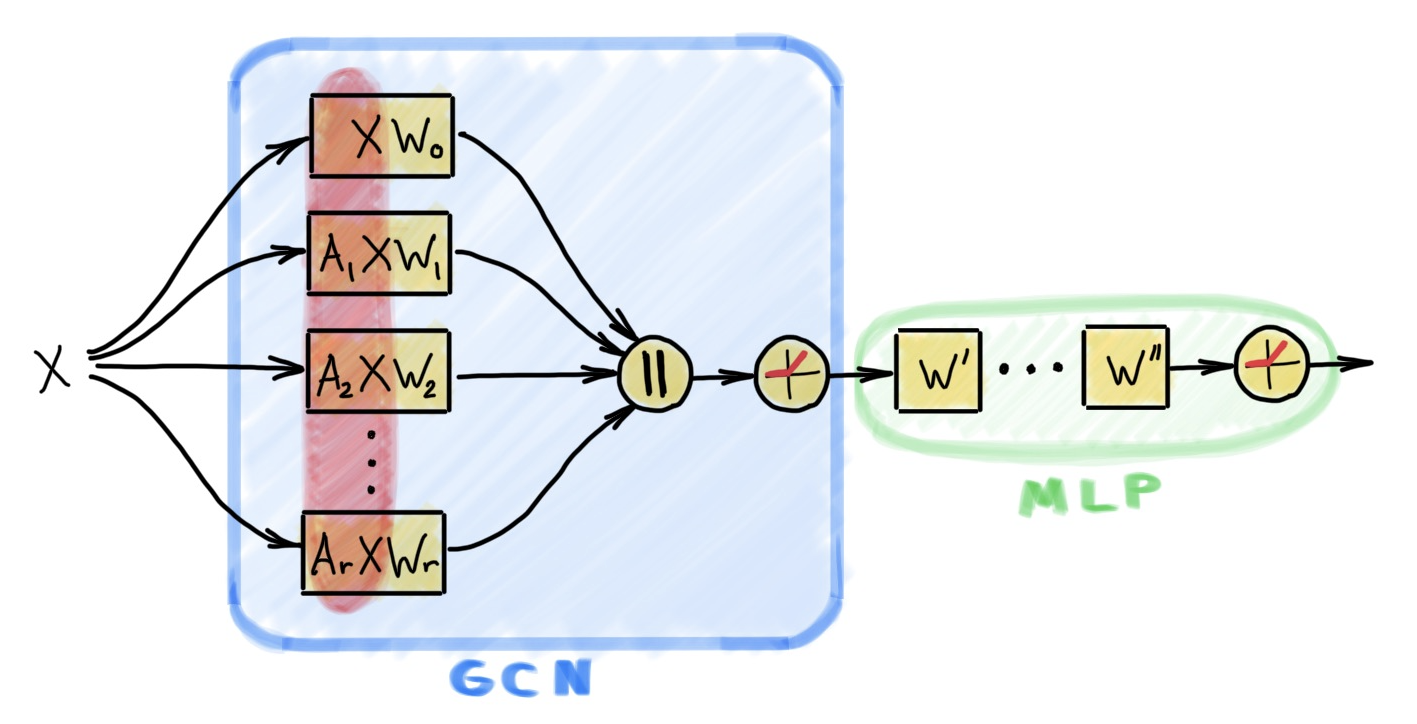 WorkshopSIGN: Scalable Inception Graph Neural NetworksEmanuele Rossi, Fabrizio Frasca, Ben Chamberlain, and 3 more authorsICML Workshop on Graph Representation Learning, 2020
WorkshopSIGN: Scalable Inception Graph Neural NetworksEmanuele Rossi, Fabrizio Frasca, Ben Chamberlain, and 3 more authorsICML Workshop on Graph Representation Learning, 2020Graph representation learning has recently been applied to a broad spectrum of problems ranging from computer graphics and chemistry to high energy physics and social media. The popularity of graph neural networks has sparked interest, both in academia and in industry, in developing methods that scale to very large graphs such as Facebook or Twitter social networks. In most of these approaches, the computational cost is alleviated by a sampling strategy retaining a subset of node neighbors or subgraphs at training time. In this paper we propose a new, efficient and scalable graph deep learning architecture which sidesteps the need for graph sampling by using graph convolutional filters of different size that are amenable to efficient precomputation, allowing extremely fast training and inference. Our architecture allows using different local graph operators (e.g. motif-induced adjacency matrices or Personalized Page Rank diffusion matrix) to best suit the task at hand. We conduct extensive experimental evaluation on various open benchmarks and show that our approach is competitive with other state-of-the-art architectures, while requiring a fraction of the training and inference time. Moreover, we obtain state-of-the-art results on ogbn-papers100M, the largest public graph dataset, with over 110 million nodes and 1.5 billion edges.
@article{rossi2020sign, title = {SIGN: Scalable Inception Graph Neural Networks}, author = {Rossi, Emanuele and Frasca, Fabrizio and Chamberlain, Ben and Eynard, Davide and Bronstein, Michael and Monti, Federico}, year = {2020}, journal = {ICML Workshop on Graph Representation Learning}, arxiv = {2004.11198}, }
2019
- KDD
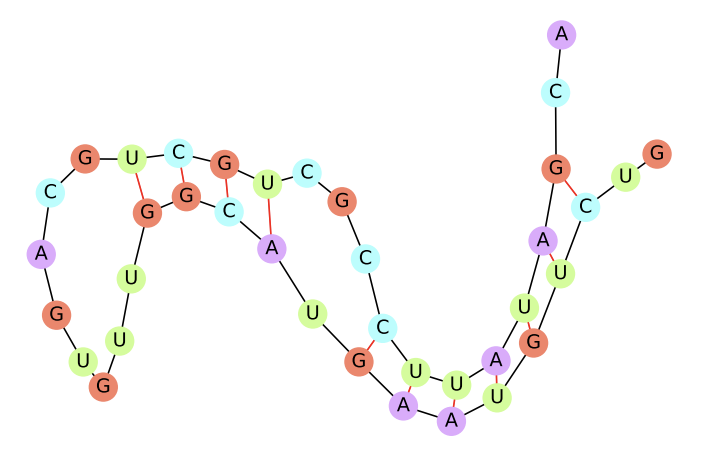 WorkshopncRNA Classification with Graph Convolutional NetworksEmanuele Rossi, Federico Monti, Michael Bronstein, and 1 more authorKDD Workshop on Deep Learning on Graphs, 2019
WorkshopncRNA Classification with Graph Convolutional NetworksEmanuele Rossi, Federico Monti, Michael Bronstein, and 1 more authorKDD Workshop on Deep Learning on Graphs, 2019Non-coding RNA (ncRNA) are RNA sequences which don’t code for a gene but instead carry important biological functions. The task of ncRNA classification consists in classifying a given ncRNA sequence into its family. While it has been shown that the graph structure of an ncRNA sequence folding is of great importance for the prediction of its family, current methods make use of machine learning classifiers on hand-crafted graph features. We improve on the state-of-the-art for this task with a graph convolutional network model which achieves an accuracy of 85.73% and an F1-score of 85.61% over 13 classes. Moreover, our model learns in an end-to-end fashion from the raw RNA graphs and removes the need for expensive feature extraction. To the best of our knowledge, this also represents the first successful application of graph convolutional networks to RNA folding data.
@article{rossi2019ncrna, title = {ncRNA Classification with Graph Convolutional Networks}, author = {Rossi, Emanuele and Monti, Federico and Bronstein, Michael and Lio, Pietro}, journal = {KDD Workshop on Deep Learning on Graphs}, year = {2019}, arxiv = {1905.06515}, }